




Deep Reinforcement Learning is the combination of Reinforcement Learning and Deep Learning and it is also the most trending type of Machine Learning at this moment because it is being able to solve a wide range of complex decision-making tasks that were previously out of reach for a machine to solve real-world problems with human-like intelligence.
Artificial Intelligence and Deep Reinforcement Learning
Exciting news in Artificial Intelligence (AI) has just happened in recent years. For instance, AlphaGo defeated the best professional human player in the game of Go. Or last year, for instance, our friend Oriol Vinyals and his team in DeepMind showed the AlphaStar agent beat professional players at the game of StarCraft II. Or a few months later, OpenAI’s Dota-2-playing bot became the first AI system to beat the world champions in an e-sports game. All these systems have in common that they use Deep Reinforcement Learning (DRL). But what is AI and DRL?
AI, the main field of computer science in which Reinforcement Learning (RL) falls into, is a discipline concerned with creating computer programs that display humanlike “intelligence”. Machine Learning (ML) is one of the most popular and successful approaches to AI, devoted to creating computer programs that can solve automatically problems by learning from data.
RL is one of the three branches in which ML techniques are generally categorized:
- Supervised Learning is the task of learning from tagged data and its goal is to generalize.
- Unsupervised Learning is the task of learning from unlabeled data and its goal is to compress.
- Reinforcement Learning is the task of learning through trial and error and its goal is to act.
Orthogonal to this categorization we can consider a powerful recent approach to ML, called Deep Learning (DL), topic of which we have discussed extensively in previous posts. DL is not a separate branch of ML, so it’s not a different task than those described above. DL is a collection of techniques and methods for using neural networks to solve ML tasks, either Supervised Learning, Unsupervised Learning, or Reinforcement Learning and we can represent it graphically in the following figure:

RL can solve the problems using a variety of ML methods and techniques, from decision trees to SVMs, to neural networks. However, in this series, we only use neural networks; this is what the “deep” part of DRL refers to after all. However, neural networks are not necessarily the best solution to every problem. For instance, neural networks are very data-hungry and challenging to interpret, but without doubts neural networks are at this moment one of the most powerful techniques available, and their performance is often the best.
Reinforcement Learning: Learning by interacting
Learning by interacting with our environment is probably the first approach that comes to our mind when we think about the nature of learning. It is the way we intuit that an infant learns. And we know that such interactions are undoubtedly an important source of knowledge about our environment and ourselves throughout people’s lives, not just infants. For example, when we are learning to drive a car, we are completely aware of how the environment responds to what we do, and we also seek to influence what happens in our environment through our actions. Learning from the interaction is a fundamental concept that underlies almost all learning theories and is the foundation of Reinforcement Learning.
The approach of Reinforcement Learning is much more focused on goal-directed learning from interaction than are other approaches to Machine Learning. The learning entity is not told what actions to take, but instead must discover for itself which actions produce the greatest reward, its goal, by testing them by “trial and error.” Furthermore, these actions can affect not only the immediate reward but also the future ones, “delayed rewards”, since the current actions will determine future situations (how it happens in real life). These two characteristics, “trial and error” search and “delayed reward”, are two distinguishing characteristics of reinforcement learning that we will cover throughout this series of posts.
Basic terminology of Reinforcement Learning
The two core components in a RL system are:
- An Agent, that represents the “solution” , which is a computer program with a single role of making decisions to solve complex decision-making problems under uncertainty.
- An Environment, that is the representation of a “problem”, which is everything that comes after the decision of the Agent.
For example, in the case of tic-tac-toe game, we can consider that the Agent is one of the players and the Environment includes the board game and the other player.
-
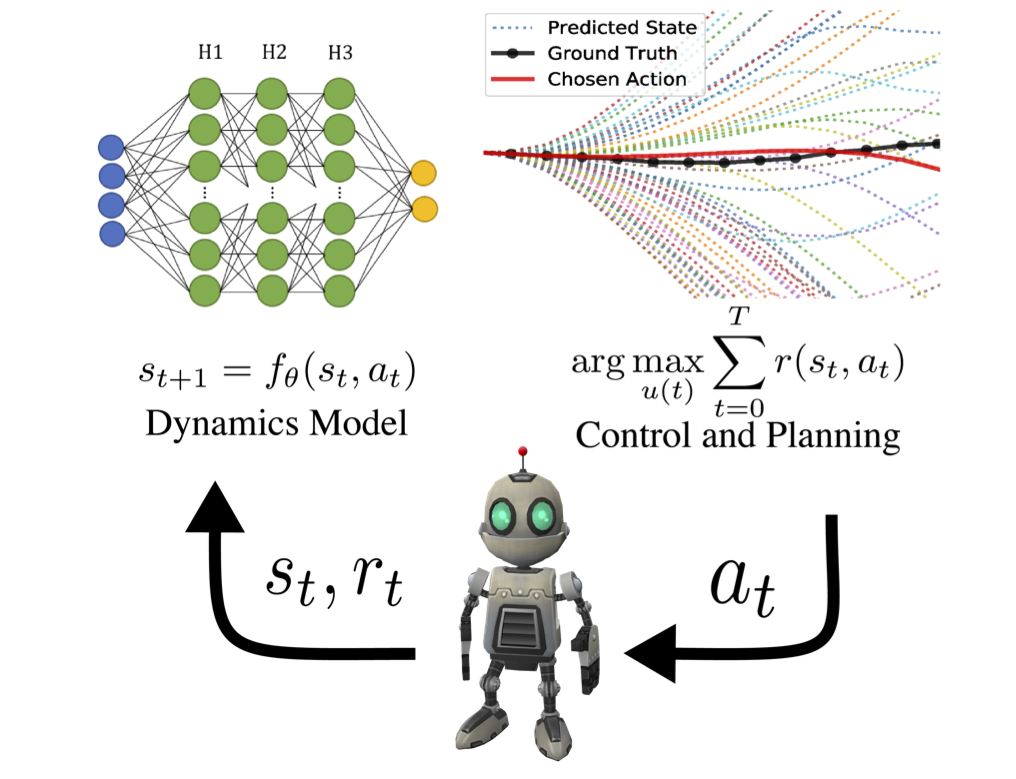
These two core components interact constantly in a way that the Agent attempts to influence the Environment through actions, and the Environment reacts to the Agent’s actions. How the environment reacts to certain actions is defined by a model which may or may not be known by the Agent, and this differentiates two circumstances:
-
When the Agent knows the model we refer to this situation as a model-based RL. In this case, when we fully know the Environment, we can find the optimal solution by Dynamic Programming. This is not the purpose of this post. When the Agent does not know the model, it needs to make decisions with incomplete information; do model-free RL or try to learn the model explicitly as part of the algorithm.
The Environment is represented by a set of variables related to the problem (very dependent on the type of problem we want to solve). This set of variables and all the possible values that they can take are referred to as the state space. A state is an instantiation of the state space, a set of values the variables take.
Due that we are considering that the Agent doesn’t have access to the actual full state of the Environment, it is usually called observation the part of the state that the Agent can observe. However, we will often see in the literature observations and states being used interchangeably and so we will do in this series of posts.
At each state, the Environment makes available a set of actions, from which the Agent will choose an action. The Agent influences the Environment through these actions and the Environment may change states as a response to the action taken by the Agent. The function that is responsible for this mapping is called in the literature transition function or transition probabilities between states.
The Environment commonly has a well-defined task and may provide to the Agent a reward signal as a direct answer to the Agent’s actions. This reward is a feedback of how well the last action is contributing to achieve the task to be performed by the Environment. The function responsible for this mapping is called the reward function or reward probabilities. As we will see later, the Agent’s goal is to maximize the overall reward it receives and so rewards are the motivation the Agent needs in order to act in a desired behavior.
Let’s summarize in the following figure the concepts introduced earlier in the Reinforcement Learning cycle:
