




Paper details
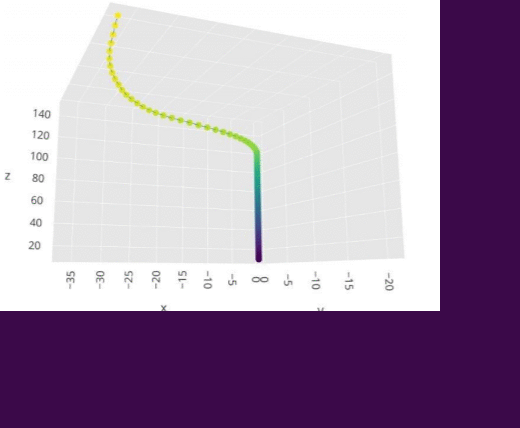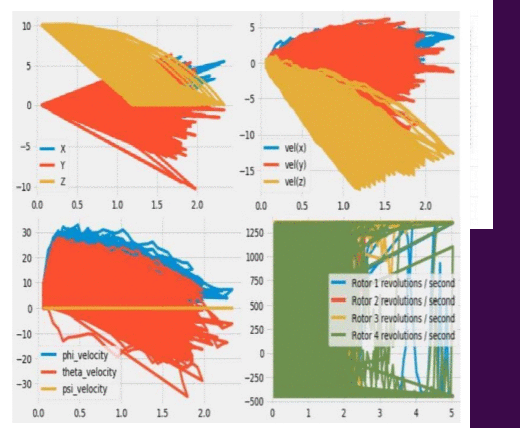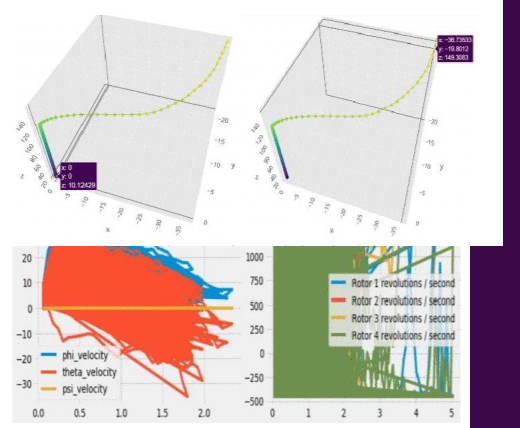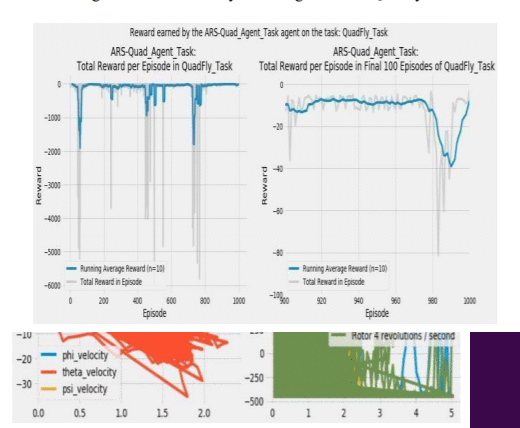
Model-based reinforcement learning strategies are believed to exhibit more significant sample complexity than model-free strategies to control dynamical systems,such as quadcopters.This belief that Model-based strategies that involve the use of well-trained neural networks for making such high-level decisions always give better performance can be dispelled by making use of Model-free policy search methods.This paper proposes the use of a model-free random searching strategy,called Augmented Random Search(ARS),which is a better and faster approach of linear policy training for continuous control tasks like controlling a Quadcopters flight.The method achieves state-of-the-art accuracy by eliminating the use of too much data for the training of neural networks that are present in the previous approaches to the task of Quadcopter control.The paper also highlights the performance results of the searching strategy used for this task in a strategically designed task environment with the help of simulations.Reward collection performance over 1000 episodes and agents behavior in flight for augmented random search is compared with that of the behavior for reinforcement learning state-of-the-art algorithm,called Deep Deterministic policy gradient(DDPG).Our simulations and results manifest that a high variability in performance is observed in commonly used strategies for sample efficiency of such tasks but the built policy network of ARS-Quad can react relatively accurately to step response providing a better performing alternative to reinforcement learning strategies.